Web pages are often made to give information to the student (presentational mode), but
to actively engage students, it can be useful to get information back from the student (interactive mode). An element or object needs to be inserted into the web page that allows the student to give input. Three
steps
are needed to make it possible for someone to type information into a
web
page:
A Form sets up an area on the page
in which interactive elements (Form Objects or Form Fields) may be placed. The Form is not actually visible on your final web page.
Form fields such the text box, textarea,
drop-down
menu, and radio button,
create places within the Form on
the
page where the information may be entered.
Once the information has been entered, the student should be able to do
something with it. Information in form fields could be mailed to the
teacher,
processed with a cgi-script computer program, processed with a
JavaScript
computer program, manipulated by an ASP page, printed, or even visually checked
by the student against a suggested answer provided by the teacher.
In this lesson we will add interactivity on a web page by setting
up a form, making some form fields, and mailing student input to the
teacher (or simply printing the page with the student input).
Setting up a Form :
<form>
</form>
Interactive fields must be located
within
a Form.
A web page form is easy to set up, however forms can be confusing to beginners because they are NOT visible in your web browser. This is where we need to become "the man behind the curtain." This can be done by inserting the form tags while editing a page in KompoZer.
Everything between the open form tag <form>
and the close form tag </form>
is part of the form, and any data entry fields (form fields) must be located inside of a form
in order to work.
The <form>
tag can include additional parameters that determine what the form will
do with anything that the student types, but these are not needed for our purposes.
In the following example, we see a form that will email
something
to the teacher, but your form doesn't need to be set up to do this in particular, It is enough to have just the open and close form elements.
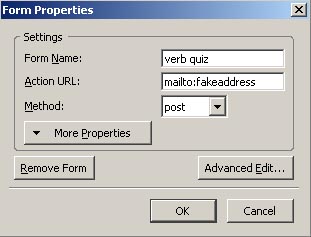
To create the Form in KompoZer, use the Insert / Form / Define Form menu item and insert the following into the window:
Form Name="verb quiz"
action="mailto:fakeaddress" method="post"
If you look at the HTML Code for the form, you will see something like :
However, all we really need for our purposes are the two simple form tags. The form elements need to be inserted within the form area, in other words between the open form tag <form> and the close form tag </form>.
You can add the <form> and </form> tags to a page by editing the Source Code and typing them in where you wish. This is sometimes easier than inserting the tags using KompoZer buttons.
It can be useful to use the split view for both Design and Source in order to better see where things are. In Design view, you will see a blue dotted line around the form area. You can even put all of the content of your page into this form area by placing the form tag after the <body> tag and the close form tag before the close body tag </body>.
Inserting Form Fields
In KompoZer, use Insert/Form/Form field... to place the elements inside the form area. Such form objects have individual names that will later allow us to manipulate them in various ways using software.
For the moment, simply getting the form elements (most importantly the textbox) on your page within a form area is enough. Practice, and when you feel comfortable doing this, then go on to the next step.
The most common mistakes students make are forgetting the <form> tags or giving multiple form elements the same name.
Processing Student Input
There are many ways to process information from the text
boxes,
textareas, menus, radio buttons, and other form fields. Most of these
involve
computer programming that is beyond the scope of this lesson. Data can
be sent to and processed by:
a cgi script - a computer program
running
on a server.
an asp web page - an active server
web page with programming built-in.
a JavaScript program - a computer
program
built-into the same web page with the original form.
The cgi script and asp
page run on a remote computer and receive form data from the student
through
the Internet. In addition to sending feedback to the student,
they
are capable of storing student responses in a database for subsequent
examination
by the teacher. These techniques are not very complicated for someone
with
basic computer programming skills but do require such skills as well as
access to certain server privileges. Most teachers will not want to tackle these.
JavaScript is a very simple
scripting
language designed for writing small programs within a web page.
It
can process information located in form objects without accessing a remote computer.
Although JavaScript is very simple as programming languages go, it is not
trivial
for a non-programmer.
But if you have a bit of Javascript code written by someone else, using it is not too difficult.
Non-programmers might get help from a programmer to create a basic
general
purpose routine to do something with student input and then reuse this same program on multiple web pages. One may also find sample utilities online that can
be used as is or slightly modified and integrated into your pages.
It is possible to find utilities that will allow the answers to be stored.
Even without a JavaScript utility, the student might
simply
type in their responses and then press the Print button on the
browser
window to print out the answers and hand them in to the teacher.
Using pop-up windows to
provide
feedback
Providing an online answer key or placing answers in pop-up
windows may be more manageable in many cases. This method allows the
student
to check his or her own answers against the teacher's model. See
our lesson on glossing or annotating
tests
for the technical details. The following new form shows examples of how
the pop-up window technique might work for the same set of questions
shown
above:
These pop-up windows use JavaScript, but there are other
techniques
that can also work.
For instance, you could place answers on a separate web page answer sheet that opens in a new window. Answers
Summary
Form fields help make your web pages more interesting by engaging
the
students actively. Many techniques can be used:
A computer program manipulating or capturing the student answers
A mailto submission sending student responses to the teacher
A JavaScript utility providing format for printing
Pop-up windows or full web page answer keys helping students check
their
work
Hiding the answer on the page and revealing it when approriate
Printing the web page itself with the answers to be handed in
By having the student do something with the language and actually manipulate information on the screen, the page becomes
interactive and helps limit the potential passivity of any medium that
sends information only in one direction.
Some of these sites are appropriate for relative beginners, but others may be considerably more complex.